Making AI Document Workflows Trustworthy: Validation and Human Review
You do not fix model uncertainty by deciding whether to trust it. You design around it.

There is a familiar tension in any conversation about putting a large language model into a business process. The models are genuinely capable: they can read unstructured documents, summarize them, classify them, and extract details a person would otherwise spend hours locating. But they are also non-deterministic. Ask the same question twice and you may get two different answers. Ask once and you may get a confident answer that is simply wrong.
The mistake is to treat this as a question of how much to trust the model. Trust it fully, and you risk silent errors that surface months later in an audit. Distrust it completely, and you end up with a process no faster than the manual one it replaced.
A more useful framing is that you do not fix the model's uncertainty by deciding whether to trust it. You design around it.
The model is the non-deterministic part of the system. Everything around it — validation, comparison, routing, review, approval, and audit — can be deterministic, observable, and governed. The job of workflow design is to wrap that unpredictable core in a structure that catches the errors it will inevitably produce.

Deterministic Validation as a Governing Layer
The most direct lever is to make the boundary around the model's output deterministic, even though the output itself is not.
Schemas are the first part of this. If you ask a model to extract the parties, effective date, and renewal terms from a contract, you should not accept free-form prose in return. You define a structured shape — a JSON schema, a typed object, or whatever fits your stack — and validate every response against it before it moves downstream. This does not prove the content is correct, but it does prove the form is usable. A field that should contain a date but comes back as "sometime next quarter" is caught at the door instead of three steps later.
Regular expressions are another useful control, especially where the format itself carries meaning. A purchase order number, postal code, currency amount, statutory reference, or account number has a shape that can often be defined precisely. When a model returns a value that claims to be one of those things, a regex check can confirm that it actually looks like one.
These checks are not sophisticated, and that is the point. They are cheap, fast, and predictable. They filter out a meaningful share of plausible-looking nonsense before a person ever sees it. You cannot make the model deterministic, but you can insist that its output pass through a deterministic layer before it affects the rest of the process.
Cross-Checks and Deterministic Comparison
Some errors slip past schema and pattern validation because they are well-formed but wrong. This is where cross-checks become useful.
Consider a statement of work that lists project milestones. One approach is to ask the model a narrow question first: how many milestones does this agreement contain? Then, in a separate step, ask the model to extract the milestones themselves, including each description and date.
Now the workflow has two related outputs that can be compared. If the first step says there are seven milestones and the extraction returns five, the system does not know which answer is right, but it does know something is wrong — and a silent failure has become a visible flag.
The two steps can use the same model, but they may be stronger if they use different models or different prompts, so that a blind spot in one path is less likely to be repeated in the other. The comparison itself is deterministic. It is just an equality check, count comparison, or consistency rule, even though the inputs came from non-deterministic sources.
Agreement does not guarantee correctness, but it raises confidence. Disagreement does not require guessing; it routes the item for review.
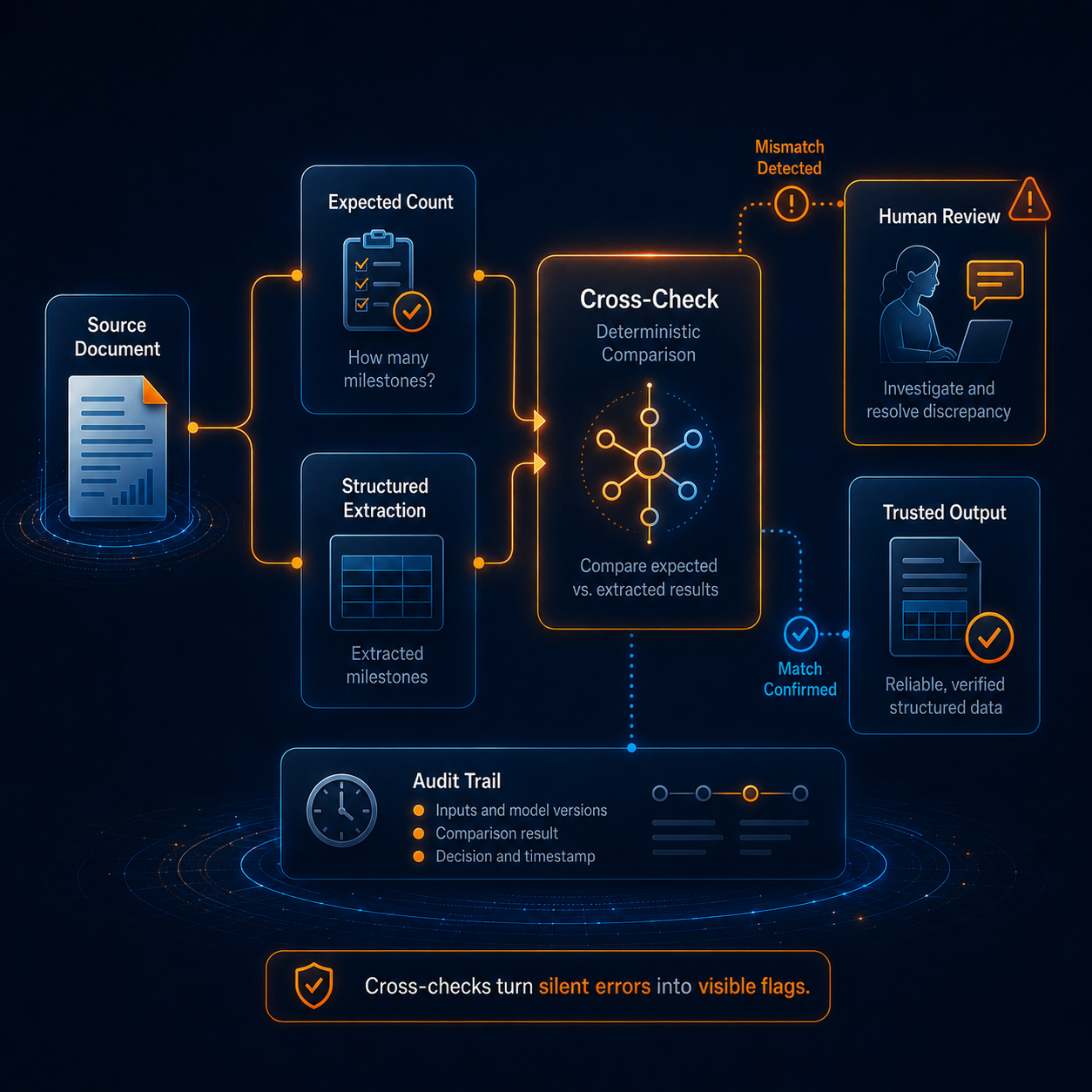
Human Review, Placed Deliberately
None of this removes the need for human judgment. It changes where that judgment is spent.
The mistake is to treat human review as a uniform layer applied to everything. That is expensive, slow, and often less safe than it appears. Reviewers asked to check every output eventually stop reading carefully.
A better approach is to flag for review only the cases that actually warrant a second set of eyes: outputs that failed validation, extractions where cross-checks disagreed, results that fall below a confidence threshold, or document types where the cost of an error is too high for automated checks alone.
Designed this way, human review becomes a deliberate part of the workflow rather than a safety blanket draped over all of it. Reviewers see fewer items, each flagged for a reason, and their attention goes to the cases where it can change the outcome. The deterministic layers handle the volume. People handle the ambiguity. That division is what makes the process faster and more trustworthy than either the fully manual or fully automated version.
Customizing the Model for the Task
There is also work to be done on the model itself. It is worth resisting the assumption that one model and one prompt should serve every step.
A clear, specific prompt that states the task, the expected format, and the edge cases to watch for will outperform a vague one by a wide margin. A small set of well-chosen examples — the actual kinds of documents you process, with the answers you expect — can improve performance further.
Where the task is narrow, repetitive, and high-volume, fine-tuning or a smaller specialized model may be more accurate and less expensive than a large general-purpose model. Different steps in the same workflow may also call for different models: a stronger model for nuanced extraction, a faster and cheaper one for a simple count, classification, or routing decision.
The principle is to match the model and its configuration to the specific job, rather than choosing a single default and hoping it generalizes. Customization is not a one-time setup step. It is part of how the workflow is tuned over time.
Prompts and Models Need Change Control
That last point matters because carefully built AI workflows can quietly degrade.
A prompt is part of the system. A model version is a dependency. Changing either can shift behavior in ways that are not obvious from a few manual tests. A newer model may be better on average but worse on the document types you care about most. A reworded prompt may fix one failure mode while introducing another.
The discipline that helps is the same one software teams already use for code. Keep a representative set of documents with known, correct answers, and run prompt changes and model upgrades against that regression set before they reach production. Compare the new results to the old ones, and look for what got worse, not only what improved. Version your prompts. Record which model and prompt were used for each run. Decide deliberately when to adopt a new model instead of upgrading by default.
None of this is exotic, but it needs to be part of the workflow from the start. It is much harder to bolt on after the process is already live and trusted.
Auditability Is Part of Trust
A dependable AI workflow should also leave a record of what happened.
Which model was used? Which prompt version? What validation rules passed or failed? Was a confidence threshold applied? Did a reviewer override the result? Was the document approved, rejected, or routed for follow-up?
These details matter because trust is not only about whether an output seems right in the moment. It is also about whether the organization can understand, explain, and defend the process later. For enterprise document workflows, that audit trail is not a nice-to-have. It is part of the governance model.
The Shape of a Dependable Process
The thread running through all of this is that model non-determinism is not a flaw that can be eliminated. It is a property that has to be managed.
Deterministic validation defines the boundaries the output must respect. Cross-checks and comparisons turn inconsistency into a usable signal. Human review is reserved for the cases that genuinely need judgment. Customization fits the model to the task. Change control keeps prompts and models from drifting. Audit history makes the process explainable after the fact.
This is the difference between a demo and a dependable process. A demo proves that a model can do something once. A dependable workflow surrounds that capability with enough structure, validation, review, and governance that the organization can rely on it the hundredth time, the thousandth time, and on the documents it has not seen yet.
The interesting work in applying AI to real business processes is rarely the model alone. It is everything you build around it.
How This Shapes FormKiQ
This is the thinking behind FormKiQ's AI Processing and Analysis module. AI can add real value to document workflows, but only when it operates inside a governed process. FormKiQ helps organizations connect AI extraction, classification, validation, review, approval, and audit history, so non-deterministic model outputs are managed within a structure the organization can explain and control.
Governed AI workflow review
Map a governed AI document workflow
Bring a document-heavy workflow to a working session with Regan Wolfrom, FormKiQ's Co-Founder and CTO. We'll review where AI extraction, validation, human review, audit history, and AWS deployment, security, and governance controls should fit.
- Document types and extraction goals
- Validation, confidence thresholds, and cross-checks
- Human review and exception routing
- Prompt, model, and workflow change control
- Audit trail and governance requirements
No commitment. Regan is FormKiQ's Co-Founder and Chief Technology Officer. If a deeper review makes sense, we can include additional business, implementation, or technical specialists.
Not ready to book? Get a scoped recommendation.
Share the AI document workflow you are evaluating, and we'll reply within one business day.