Records Retention in the Cloud: Why Metadata Matters More Than Storage
Cloud storage provides the foundation. Metadata provides the control layer.


Most organizations understand the basic questions behind records retention: How long do we need to keep this? Where should it live? Who should be able to access it? When can it be deleted?
Those are important questions. But in a modern cloud environment, they depend on something more foundational: does your document platform know what each record is, what policy applies to it, and what needs to happen next?
Cloud storage has made it easier than ever to retain large volumes of content. That is a major advantage. But storage alone does not create a records retention program. To manage records with confidence, organizations need context: classification, ownership, lifecycle state, retention rules, legal holds, WORM protection, disposition status, and audit history.
That context lives in metadata. And when metadata is part of the platform's operating model, retention becomes something the system can help enforce, not just something the organization has to remember.
Retention Starts with Knowing What You Have
Many organizations are not struggling because they lack storage. They are struggling because their content has outgrown the structures originally used to manage it.
A shared drive, object storage bucket, or basic document repository may hold files reliably, but it may not understand whether a document is a contract, an HR record, a financial transaction, a policy, a case file, or a regulated business record. It may know when a file was uploaded, but not which retention schedule applies. It may know who last modified it, but not whether it is under legal hold or should be protected from deletion.
That distinction matters.
A retention program depends on more than file names and folder locations. It depends on structured information about the record itself: its type, classification, business context, retention period, access requirements, and disposition rules. Without that metadata, retention often becomes a manual process supported by spreadsheets, scripts, periodic reviews, and institutional memory.
Those efforts can work for a time. But as content volumes grow, regulations change, and organizations move deeper into cloud infrastructure, manual retention processes become harder to scale and harder to prove.
Records Retention Is a Lifecycle
Records do not remain in one state forever. They move through stages: active use, semi-active reference, long-term retention, legal hold, immutable archive, and eventual disposition.
Each stage may require different controls. An active contract may need collaboration and versioning. A finalized contract may need stricter access controls. A regulated record may need WORM protection to prevent alteration or deletion during its required retention period. A record connected to litigation may need legal hold applied, even if it has otherwise reached the end of its normal retention schedule. A record eligible for disposition may need review, approval, and a defensible audit trail before destruction.
Managing that lifecycle manually creates unnecessary risk and administrative burden. Someone has to remember when a file should move. Someone has to identify which records are affected by a hold. Someone has to confirm whether a record is eligible for disposition. Someone has to reconstruct what happened if an auditor, regulator, or legal team asks for evidence.
A metadata-driven system reduces that burden by allowing lifecycle rules to operate directly from the record's classification, dates, status, relationships, and policy assignments. The goal is not to replace human judgment. It is to make sure human judgment is applied at the right points, with the right evidence, instead of relying on people to manually track every record across every stage.
Where WORM Fits
WORM, or Write Once Read Many, preserves records in a non-rewriteable, non-deletable state for a defined retention period. That makes it especially useful for legal archives, regulated records, financial documentation, and other content where the organization needs to demonstrate that records were protected from alteration or premature deletion.
But WORM is not a replacement for metadata. It is a control that depends on metadata to be used effectively. Metadata determines which records require immutable retention, when that protection should begin, how long it should last, and what should happen when the retention period expires. WORM helps enforce preservation. Metadata tells the system what to preserve, why it matters, and what should happen next.
This is why WORM, legal hold, retention schedules, and disposition workflows should not be treated as separate tools. They should work together as part of a single lifecycle governance model.
Metadata as Architecture, Not Annotation
There is a major difference between a platform that stores metadata about documents and a platform that uses metadata as part of its operating model.
In the first model, metadata is often treated as descriptive information: useful for search, filtering, or reporting, but separate from how the document is actually governed.
In the second model, metadata drives action. It can determine access control, lifecycle state, retention period, legal hold status, immutability controls, review requirements, storage tiering, and disposition eligibility.
That is where metadata becomes architecture.
The document is still the core asset. But metadata provides the intelligence needed to manage that asset over time. It connects the record to the business process, policy framework, regulatory requirement, and lifecycle stage that give it meaning.
A file cannot tell you why it must be kept for seven years. A folder path cannot prove that the correct disposition process was followed. A timestamp alone cannot explain whether a record was under legal hold, protected by WORM, or approved for destruction. The evidence comes from metadata and the audit trail around it.

Why Storage-First Approaches Reach Their Limit
Cloud storage is powerful, durable, and cost-effective. It has transformed how organizations manage large volumes of content. But when storage becomes the primary organizing model, records governance can become difficult.
A storage-first approach often requires a parallel governance layer: spreadsheets that map folder structures to retention schedules, scripts that identify aged files, manual review queues, and separate logs used to reconstruct lifecycle events. These can be practical starting points, especially during a transition from legacy systems. But over time, they become harder to maintain.
The challenge is not that organizations have made poor choices. In many cases, they made sensible choices for the stage they were in. Shared drives, cloud buckets, and lightweight repositories often begin as practical solutions to immediate problems.
The issue is that records requirements tend to mature. Audit expectations increase. Legal and compliance teams need stronger evidence. Business units create more content. AI and automation introduce new classification opportunities. Retention rules become more nuanced. At that point, the organization needs more than storage. It needs a governance layer that is built into the document platform itself.
What This Looks Like in Practice
Consider an organization managing multiple types of regulated records: contracts, HR documents, financial records, correspondence, policies, and operational files. Each record type may have a different retention period. Some may require WORM-based protection. Some may require approval before disposition. Some may become subject to legal hold. Some may need to be retained because of a regulatory schedule, while others may be retained because of a business process or contractual obligation.
In a metadata-driven system, those rules can be connected directly to the document's classification and lifecycle state. A contract can inherit a retention schedule when it is finalized. A financial record can be protected with immutable retention controls for the required period. A legal hold can suspend disposition for all records associated with a matter. A disposition workflow can require review and approval before destruction. And an audit trail can show what happened, when, why, and by whom.
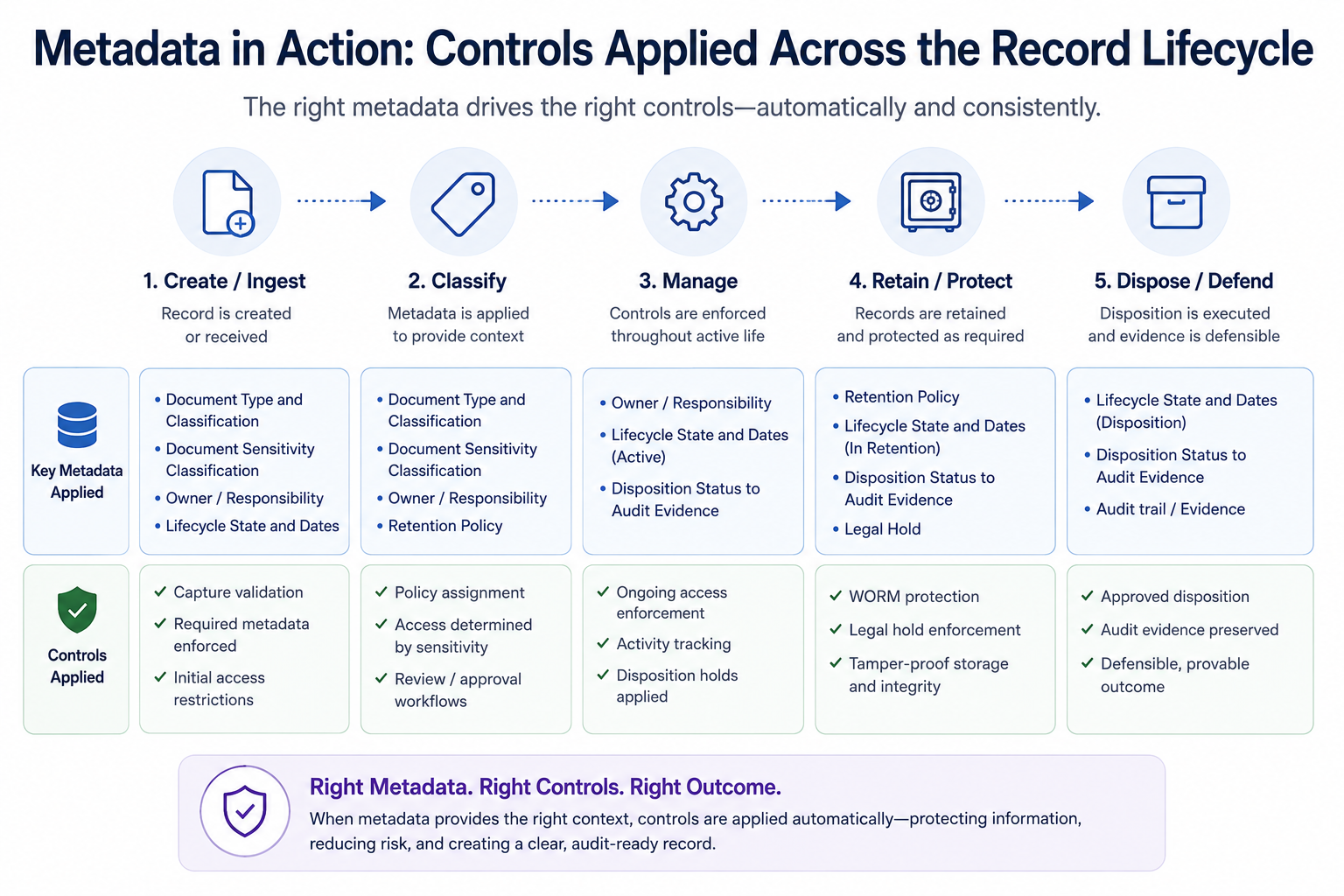
The result is not just better automation. It is better evidence. The organization can demonstrate that records were classified, governed, protected, retained, reviewed, and disposed of according to policy. That is what regulators, auditors, and legal teams are looking for: not a description of storage architecture, but proof that the organization maintained control throughout the record's lifecycle.
Building for Governance in the Cloud
The move to cloud-based document management gives organizations an opportunity to modernize records retention instead of recreating older patterns in newer infrastructure.
That starts with defining what the organization needs to know about its records: what types of records it manages, which retention schedules apply, which records require immutable protection, how legal holds are applied and released, who can approve disposition, and what evidence is needed for audits, discovery, and internal governance.
Once those questions are clear, the platform can enforce the rules more consistently.
At FormKiQ, this is the direction we have taken: metadata-driven lifecycle governance, configurable retention and disposition processes, legal hold support, auditability, and WORM-based protection for records that require immutable retention.
With these capabilities working together, organizations can manage records based on what they are, what policies apply to them, and what evidence needs to be preserved over time. The goal is not to force teams into rigid legacy models or leave them with storage-only repositories that require manual workarounds. It is to help them strengthen the governance practices they already care about, using cloud-native infrastructure designed for control, traceability, and scale.
Cloud storage provides the foundation. Metadata provides the control layer. WORM, legal hold, and disposition workflows provide the enforcement. Together, they make records retention more scalable, more defensible, and easier to manage over time.
Michael O'Regan is Business Solutions Consultant at FormKiQ, an AWS-native document and information management platform built for metadata-driven lifecycle governance, retention, disposition, legal hold, and WORM-based records protection. To learn more, visit formkiq.com.