Document Processing: Getting Documents and Data Into Your Org - How FormKiQ Reduces Costs and Enhances Efficiency
Empowering modern enterprises through advanced automation and intelligent integration

Intelligent document processing (IDP) is transforming how organizations handle unstructured data, enabling faster, more accurate, and more scalable document management. As businesses increasingly adopt digital solutions, the need for robust document automation has never been greater. FormKiQ offers a powerful platform designed to streamline document workflows, reduce manual effort, and expand on information processing capabilities.
By integrating intelligent document processing into broader business processes, organizations can automate and optimize end-to-end functions, enhancing efficiency, accuracy, and scalability. FormKiQ's platform empowers business users to automate processes without heavy reliance on manual inputs, making it easier to drive digital transformation across the enterprise.
The Sea Change
The recent advances in cloud computing and artificial intelligence are creating an opportunity for organizations to upgrade their information processing, while reducing their overall cost. IDP solutions can process both structured and unstructured documents, as well as semi structured documents and paper based documents, enabling comprehensive automation across diverse document types.
This isn’t just an excellent way to increase profit, but also a key strategy in remaining competitive against both larger players as well as nimble new upstarts.
FormKiQ is leading the way with our event-driven document and information management platform. By deploying FormKiQ directly into an AWS account under the organization’s control, it’s possible to reduce or eliminate manual processes, increase accuracy, and expand on information processing capabilities through a robust document processing solution.
This is a major improvement over what was previously available for information processing, as document processing solutions now automate processing workflows and processes data, reducing the need to enter data manually and minimizing human errors.
What is Intelligent Document Processing (IDP)?
Intelligent Document Processing (IDP) is transforming the way organizations handle documents and data by automating the extraction of relevant information from a wide variety of document formats. Leveraging advanced automation technologies such as natural language processing (NLP), optical character recognition (OCR), and machine learning, IDP solutions can process both structured and unstructured documents—including paper documents, digital documents, and scanned documents—with remarkable speed and accuracy.
At its core, intelligent document processing involves several key steps:
- Document Classification: Using machine learning and artificial intelligence, IDP systems automatically categorize incoming documents—such as invoices, contracts, or patient records—ensuring that each document type is routed to the appropriate processing workflow.
- Data Extraction: Through technologies like optical character recognition (OCR) and NLP, IDP solutions extract key information from document images, scanned documents, and digital forms. This enables organizations to capture valuable insights from both structured data and unstructured data, including handwritten text and complex documents.
- Data Validation: To ensure data accuracy, IDP platforms often incorporate robotic process automation (RPA) and, when necessary, human review. This step helps validate data, reducing the risk of human error and ensuring that only high-quality, actionable data enters business systems.
By automating manual data entry and repetitive tasks, intelligent document processing significantly reduces operational costs and processing times. Businesses benefit from improved data accuracy, faster turnaround, and the ability to process large volumes of documents—whether for invoice processing, claims processing, expense management, or fraud detection. IDP solutions are especially valuable in industries such as healthcare (for patient records and insurance claims), finance (for financial documents and compliance), and human resources (for resumes and employee records).
The benefits of intelligent document processing extend beyond efficiency. By extracting data from unstructured documents and converting it into structured, actionable data, organizations can enhance business process automation, improve customer relationship management, and gain valuable insights for decision-making. IDP solutions also support digital transformation initiatives by enabling seamless integration with existing business systems and reducing reliance on manual labor.
In summary, intelligent document processing (IDP) empowers organizations to process documents and extract relevant information with greater speed, accuracy, and scalability. By leveraging advanced automation, computer vision, and machine learning, IDP solutions help businesses organize documents, streamline data entry, and unlock the full potential of their business data.

The Costs of Manual Data Entry and Limitations of Basic Import Tools
For most organizations, processing a steady stream of both digital and physical documents is a daily reality. However, the traditional methods used to handle this influx—manual data entry and basic import tools—often fall short.
Manual Data Entry Challenges:
- Errors and Inconsistencies: Human error is a significant risk with manual data entry, leading to inaccuracies that can affect everything from financial reporting to customer relations.
- Inefficiency: Entering data manually creates bottlenecks and slows down workflows. Manual processing is time-consuming, diverting resources from more strategic tasks and slowing overall response times.
- High Costs: The labor-intensive nature of manual data entry not only spikes payroll expenses but also incurs additional costs from correcting errors and inefficiencies.
- Scalability Issues: As business volumes grow, the inefficiency of manual data entry becomes increasingly untenable, hindering potential growth due to its limited scalability.
Limitations of Basic Import Tools:
- Restricted Functionality Most basic tools only allow for simple uploading and storage of documents without supporting advanced data processing, which is critical for extracting actionable insights.
- Minimal Data Extraction: While some tools offer rudimentary OCR capabilities, they lack the sophisticated algorithms needed for deeper data interpretation essential for accurate decision-making.
- Integration Challenges: These tools often operate in isolation with limited ability to seamlessly integrate with other core business systems, restricting the flow of data across the enterprise.
- Limited Validation and Flexibility: Basic import tools frequently lack robust validation features to ensure data integrity and offer little flexibility to adapt to changing business requirements, making them less effective as organizations evolve.
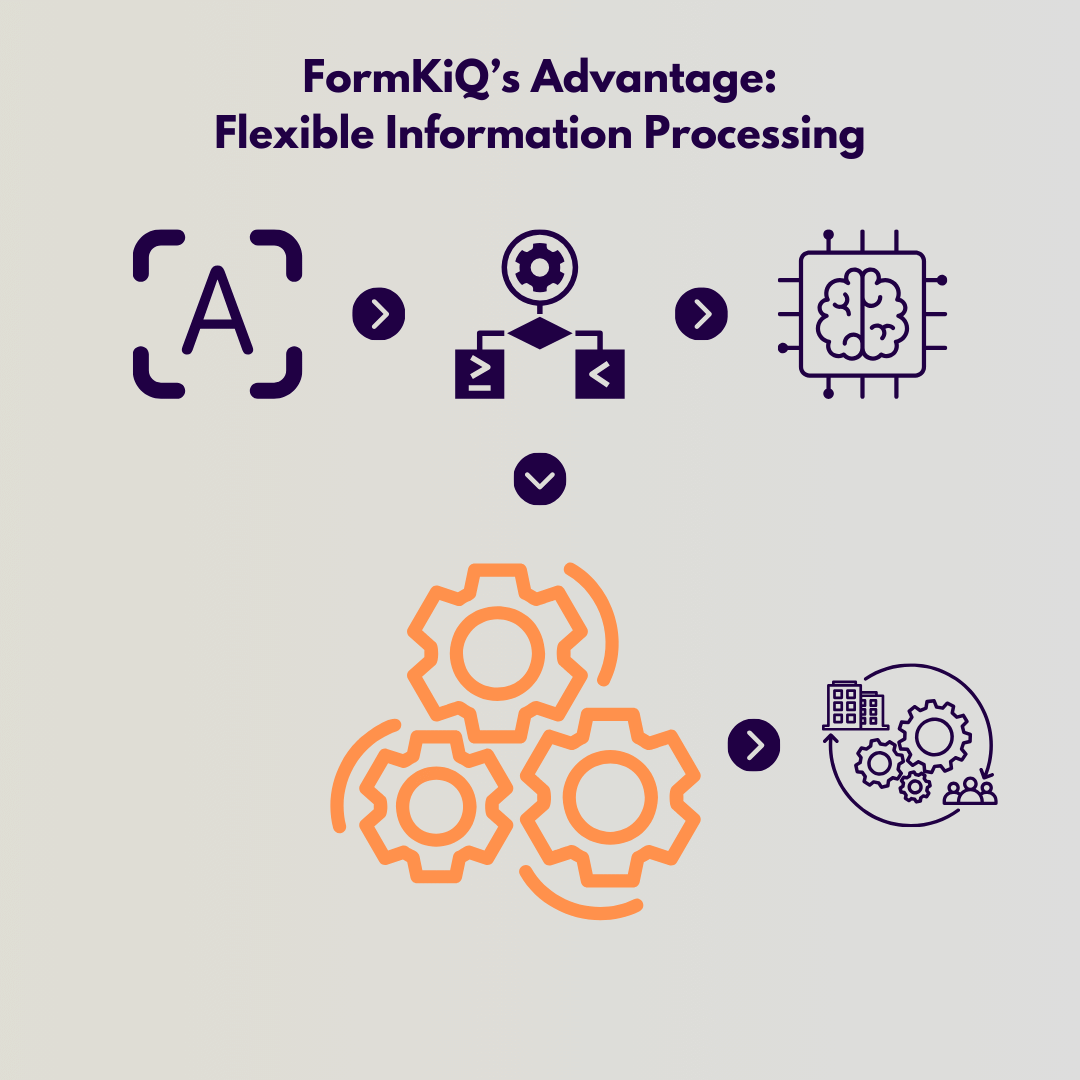
Our Information Processing Innovations
At FormKiQ, our approach to enhancing import tools involves increasing the flexibility and customization available in import workflows and specific actions. By employing a combination of rules-based processing and cost-effective large language models (AI), we significantly reduce the need for manual intervention.
Utilizing well-established services such as Amazon Textract and Amazon Bedrock, coupled with sophisticated intelligent document processing algorithms and robust rule-handling capabilities, FormKiQ offers a more dependable and efficient method for document and data intake, achieving a higher degree of automation.
Moreover, the data extracted from these documents can be converted into formats suitable for integration with enterprise software applications like SAP, NetSuite, and Salesforce. The documents are systematically categorized and stored within an organization’s Amazon account, making them readily available for auditing, reporting, or later retrieval.
These processes are managed via the FormKiQ API and through the use of FormKiQ’s Rulesets and Workflows. FormKiQ orchestrates document processing work by managing the entire sequence from document intake, through classification and extraction, to integration with business workflows. This system allows incoming documents to be assessed and organized by applying a classification schema, generating attributes such as tags and metadata, and determining the necessary actions for each document.
This not only reduces the manual workload and associated costs but also lowers core processing costs due to the scalable and adaptable architecture of FormKiQ, which aligns with the AWS Well-Architected Framework.
Furthermore, FormKiQ’s adaptable multi-step document processing system enhances cost-efficiency; it initially handles the extraction of document attributes through programmatic and rules-based processing. Documents requiring more detailed processing are then directed to specific AI-driven extraction steps as needed. Any documents with issues that require manual review, such as incomplete data, are routed to a queue for further inspection.
These advancements enable FormKiQ to offer enhanced processing capabilities that adapt and scale with an organization’s demands, thereby minimizing manual involvement and reducing the total cost of ownership.
FormKiQ’s Advantage at Work
As of May 2024, we provide these functionalities across various industries, including HR, education, and retail. The adaptability of FormKiQ’s information processing allows any sector to quickly and efficiently utilize this technology.
If you have a use case that could benefit from FormKiQ’s flexible information processing, please reach out. We can go over your requirements and create and demo a detailed plan that meets the needs of your organization.