Where documents get lost in traditional architectures
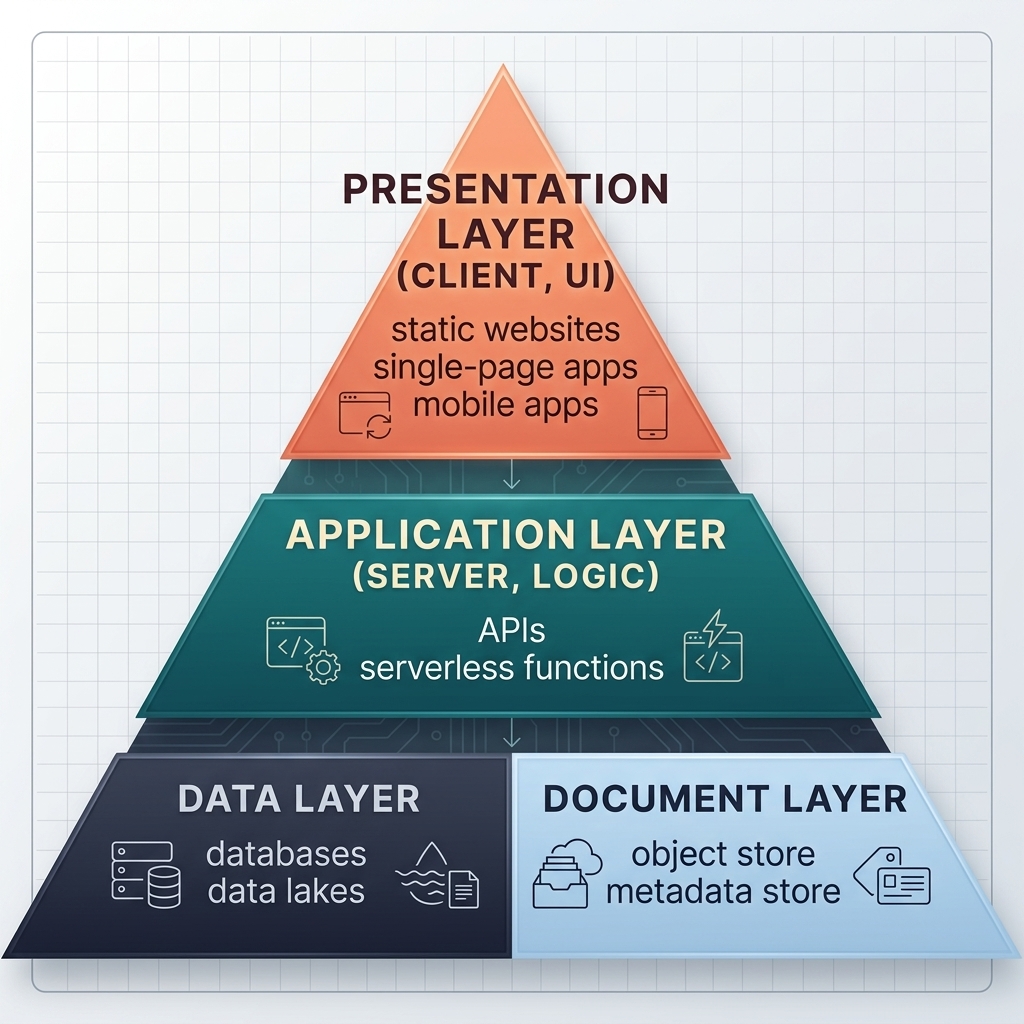
Most software architectures are built around a three-tier model: a presentation layer for the user interface, an application layer for business logic, and a data layer for structured storage. It's a well-understood pattern — and it has a blind spot.
Documents don't fit cleanly into the data layer. They're not rows in a database. They're not raw objects in a data lake. They're a combination of content and context — binary or plain-text content paired with metadata that describes what the document is, where it came from, who owns it, and what should happen to it over time.
When teams try to force documents into existing tiers, the result is familiar: files stored as database blobs with brittle metadata columns, or raw objects in S3 with no searchable structure, or documents scattered across both with no consistent retrieval model. Search breaks. Governance breaks. Retrieval at scale becomes expensive and unreliable.
The document layer is a distinct tier
The right solution is not a better blob column or a smarter data lake query. It's treating documents as a first-class architectural concern — a dedicated layer with its own storage model, its own metadata store, its own search and retrieval capabilities, and its own access and lifecycle controls.
This is the document layer: a purpose-built tier that sits alongside the data layer, handling the object store and metadata store functions that structured databases and data lakes were never designed to handle well.
What FormKiQ Core provides
FormKiQ Core is the document layer for your AWS architecture. It deploys directly into your AWS account via CloudFormation and gives your application a complete, API-first document layer from day one — without the overhead of building and maintaining one yourself.
What that includes:
Object store: Documents stored in S3, within your account, under your encryption and access policies
Metadata store: Rich, queryable metadata and custom attributes for every document, stored in DynamoDB
Full-text search: OpenSearch-powered search across document content and metadata
Processing pipeline: OCR, classification, and enrichment via Lambda — triggered on ingest or on demand
Access control: IAM-native, with RBAC and ABAC support for per-user, per-tenant, and per-document policies
Audit and lifecycle: Version history, event trails, retention controls, and defensible deletion
FormKiQ Core is open source, free to deploy, and designed to be extended. It is the foundation that FormKiQ Essentials, Advanced, and Enterprise build on — and the starting point for any team that needs a document layer they actually own.
Start with FormKiQ Core
The open-source foundation — API-first, deployable into your own AWS account, and free to use. Right for architecture validation and early implementation.
For governance-heavy environments with residency, sovereignty, assurance, and multi-jurisdiction requirements. Talk to us about the right deployment model.